I like this quote: “I recommend that since so many risks of AI systems come from within relationships where people are on the bad end of an information asymmetry, lawmakers should implement broad, non-negotiable duties of loyalty, care, and confidentiality as part of any broad attempt to hold those who build and deploy AI systems accountable.”
It seems to me that if one follows this logic, we end up with principle based legislation that will present challenge in building control models. It will take time for best practices to emerge. Do we end up with something that looks like GDPR but for Ai?
Comprehensive framework would establish an independent oversight body, allow enforcers & victims to seek legal accountability for harms, promote transparency, & protect personal data
The good thing about the way that this is written up is that many of the data and PII best practices already on the books are captured – i.e. transparency and how children’s data is managed are the two that caught my eye.
SB-362 Data broker registration: accessible deletion mechanism.(2023-2024)
Much wailing and gnashing of teeth here. This is one of those things that in principle sounds great, but in practice will be complex – maybe in this day and age that applies to all privacy data management. My biggest issue surrounds what organizations do until this all gets sorted out – what does “good” look like from the regulator perspective?
This is summed up in the following from Alex LaCasse at the IAPP “”From a purely practical perspective, in a relatively short time period, there are now many varying privacy laws that require companies to quickly and wholly change their operations and technical infrastructure, let alone their business practices that are reliant on data,” Kelley Drye & Warren Partner Alysa Hutnik, CIPP/US, said. “In the meantime, companies are devoting millions to revamp their operations to comply with these laws in good faith, knowing that realistically their interpretation of these laws may be off, and many more millions of dollars will need to be spent to course-correct based on future regulations and regulatory guidance.”
I am reminded of a comment a lawyer friend made back in 2017 when GDPR was all the rage: “if you wait until the details are sorted out in court, then you will not have wasted millions – far cheaper to pay me $60k to defend this position than to do a system upgrade and have to re do it every time legal opinions are released” (and yes he said $60k which sound too low to me!)
Form a practical perspective, I keep coming back to the core privacy principles – which basically align to GDPR and CCPA Rights and Obligations. We need to be able to execute on those rights at some level, and get those foundations in place, and be in a position to fine tune when the details emerge.
This post falls into the category of amusing stuff to do over morning coffee.
McKinsey wrote an article that is creating much discussion. I am sure this was written in good faith in an attempt to solve a management problem associated with software development teams. That article is here The response from Dave Farley – YouTube link below is pretty funny.
I no longer manage software teams, and when I last did, agile was just beginning. However, I love to keep track of all of the discussion about management techniques – generally those that are either trying to fix the mistakes of agile, or debunk it entirely. This is relevant from a data perspective, as data and applications are obviously tied together and any data project is going to get tied up into a DevSecOps or a DataOps discussion – both seeking to be agile in one form or another.
My high level take away from the McKinsey article was that they were trying to focus on the soft issues or capabilities – indeed this is the issue Farley had with the article – that the metrics were not measurable. This is typical McKinsey – they are a management consulting company after all. Farley argues that one can stick with established metrics and measures and do better. His point is that it is the production of the team that counts. However, still does not get at understanding the management challenge at the individual level. Nowadays, I would have to think that team productivity is impacted when people leave, and thus within the scope of the McKinsey discussion is the idea of retention – not a bad idea. Are you looking things as a manager – in which case retention matters, or as a developer – in which case quality and speed matter are what should be measured.
Either way, have a read and a look – amusing musings!
This presentation is from December 2019 – pre pandemic, and is the last live show I have presented in – I do look forward to getting back into that groove. The following is a write up done by Amber Dennis at DataVersity. Also posted on LLRX.com – here.
“If Google can deliver results across the entire internet in seconds, why do I have so much trouble finding things in my organization?” asked Jonathan Adams, Research Director at Infogix, at the DATAVERSITY® DGVision Conference, December 2019. In a presentation titled, “I Never Metadata I did Not Like” Adams outlined successful approaches to understanding and managing metadata.
What is Metadata?
According to the DAMA International Data Management Body of Knowledge (DAMA-DMBoK2), the common definition for metadata, ‘data about data,’ is too simple. Similar to the concept of the card catalog in a library, metadata includes information about technical and business processes, data rules and constraints, and logical and physical data structures. It describes the data itself, the concepts the data represents, and the relationships between the data and concepts. To understand metadata’s purpose, imagine a large library, with hundreds of thousands of books and magazines, but no card catalog. Without the card catalog, finding a specific book in the library would be difficult, if not impossible. An organization without metadata is like a library without a card catalog.
“Obviously it’s data about data, in that sense. We all know that, but also, one person’s data is another person’s metadata. So it gets kind of confusing,” Adams said. Metadata has traditionally focused on technical metadata, which details the structure of data and where it resides, supports IT in managing data, and assists user communities in accessing and integrating data. Reference data, which provides known vocabulary and creates business and operational context along with semantic meaning, is also metadata. Adams said:
“Metadata is kind of everything. It’s how you visualize it, and it’s how you find it. It totally enables data, and in many respects, it’s going to be the bulk of the data you have.”
Types of Metadata
Descriptive metadata is metadata about the asset, including its title, creator, subject, source, keywords, etc.
Content classification metadata details the content and meaning of the data asset. This includes relationships, data models, entities, the business glossary, controlled vocabularies, taxonomies and ontologies.
Administrative metadata details how to access and use data assets and includes lineage, structure, audit and control, and preservation information.
Usage metadata indicates how data may be used and how it must be controlled, which includes users, rights, confidentiality and sensitivity.
“And if that isn’t complicated enough,” he said, “those four types of metadata get applied slightly differently depending on where you are.”
Metadata for Operational Systems
Adams provided an illustration of an operational system using a pyramid, with reports on the top level, transactional data on the second level, then functional data on level three, master data on level four, and structural and reference data as the base of the pyramid. Types of data not included in this structure might be a data lake used by marketing, external data, financial information, or CRM data:
“This gets complicated, so we’re going to talk about simplifying it. My point here is that you should drive it from the user perspective, with that use case, view it within this context, and scope it appropriately.”
How Is Metadata Important?
Metadata answers critical questions about data:
Is the data discoverable?
Is it understandable?
Can it be accessed?
Is it usable?
Success in Metadata Management is shown by how well a team engages and aligns information to the business and operational context of the organization, Adams said. The DMBoK2 says that like other data, metadata requires management. As the capacity of organizations to collect and store increases, the role of metadata management grows in importance. To be data-drive, and organization must be metadata-driven.
Success with Metadata Management
To manage metadata, start with a framework that aligns data to business and operational contexts so that metadata can support Data Governance in the following areas:
Organizational Impact
Capabilities and Interfaces
Programs and Platforms
Repositories
Adams then further broke down how to address the governance of each of these four areas.
Organizational Impact
Metadata turns critical ‘data’ into critical ‘information.’ Critical information is data + metadata that feeds Key Performance Indicators (KPIs). He recommends asking: “What will change with a better understanding of your data?” Getting people on board involves understanding how metadata can solve problems for end users while meeting company objectives. “We want to be in a position to say, ‘I do this and your life gets better.’” To have a greater impact, he said, avoid ‘data speak’ and engage with language that the business understands. For example, the business won’t ask for a ‘glossary.’ Instead they will ask for ‘a single view of the customer, integrated and aligned across business units.’ An added benefit of using accessible language is being perceived as helpful, rather than being seen as adding to the workload.
Capabilities and Interfaces
All users must be given the capability to discover information and apply it to challenges, to share critical information, and have access to automated process when available.
Discover and Understand: A catalog search portal allows users to discover what data is available, place that data in context, and understand who can access it, and how to do so.
Communicate and Share: Users need the ability to communicate what they’ve produced and make it available for broader consumption. Complete descriptions of data are necessary for compliance and consistency, but must be available in language geared toward the user. The term ‘ETL processing’ may be adequate for an IT user, but terminology such as ‘GDPR compliance’ should also be available so business users have access to the same information.
Acquire and Integrate: Acquisition and integration varies depending on the perspective of the user and the use case. Administrative metadata enables data consumers to access and integrate data into their environment by clarifying data type, format and access rights. Configuration metadata is important for IT to perform data prep or ETL. Application Programming Interface (API) metadata shows a programmer how to integrate data into a website.
Integrate and Automate: Interactive metadata supports automated processes for communication and coordination among systems.
Programs and Platforms
Metadata supports reporting and visualization, allowing C-suite members to make better decisions. Metadata enables the transformation of operations allowing the business to grow. Labeling is critical so that data can move around the organization and be used in innovative ways. Once data is understandable, he said, “You’re going to have people using that data to derive insights that they didn’t even know they didn’t know.”
Data Repositories
Existing information architecture enables – or disables – the depth, scope and quality of available metadata. Adams said that the discussion about repositories is more enterprise architecture-driven, rather than about user needs and business priorities. “It defines what you can do going forward, and it also defines what you cannot do today.”
Reference Architecture
When documenting the Information Architecture, Adams suggests focusing on how the information flows around the architecture of the organization, rather than focusing on specific systems. Start with the type of information and where it resides and denote broad applications and system boundaries. Include data shared with people outside the organization. Although it’s critical to understand what’s happening inside the organization, from a risk perspective, when it comes to risk, it’s more important to understand what’s happening outside the organization. “The interesting thing about this is that you want to use it as a communication tool,” he said. If initially it’s too complex for business users to understand, simplify it a bit. The important thing is to bring people on board.
Data Governance
Often overlooked, governance metadata is Business Intelligence (BI) for your data: metadata about metadata. Metadata ties together Business Strategy, Data Strategy, Data Management and operations with Data Governance. “‘What is the state of my metadata across my ecosystem?’ That’s a bit of a wacky concept for people to grasp.” Enterprise architectures and data reference models are an attempt to align and understand governance policies down to the lower level, Adams said.
Metadata can provide answers to governance questions, such as:
How do I know I’m doing this correctly?
What constitutes ‘good’?
Are we deploying best practices? Are they defined?
Is this data sufficiently labeled to be considered ‘governed data?’
Building Capability
As competitive factors in the marketplace continue to evolve and change, the ability to quickly rise to meet those challenges can mean the difference between success and failure. Developing new capabilities, scaling to meet demand, and controlling risk requires the ability to pull reports using data in ways that are impossible to anticipate in advance, Adams said. “If that’s the environment you want, then you want well-labeled data that allows you to pivot, schema-on-demand kind of activity, and a very flexible perspective.”
Updated 9/14/20 with new links. It is a bit ironic that I linked to the Dataversity site, and they do not use persistent identifiers to label their data assets, so all my links are dead. Note to practitioners – if you are not using persistent identifiers your institutional knowledge captured in data assets lasts as long as the identifier!
I went looking for this deck as I was having a discussion on governance that is as old as the hills; essentially how do you link data governance activities to the business activity to address – why does data governance exist?
The other discussion that got me looking at this article again was how we go about building an operating model for organizations where the Governance team is doing more than responding to quality requests – how does the team proactively address data issues?
Both of these are tied to the article below. The Hoshin Framework (at least as it is presented below) ties strategic initiatives all the way down to identified data capabilities that can be addressed proactively to support the business strategy.
A note on the spreadsheet. This spreadsheet is not for the faint of heart. The spreadsheet supports the thought exercise used to shape discussions and your communication with stakeholders. The key point to take away is that the spreadsheet gives you the ability to relate governance budget to strategic goals, funded programs, current project and metrics. Think of it as the audit worksheets – no one ever sees those, and the auditor reports out only the results.
Original Post.
In my previous post I discussed some analytical phrases that are gaining traction. Related to that I have had a number of requests for the deck that I presented at the Enterprise Dataversity – Data Strategy & Analytics Forum. I have attached the presentation here. NOTE: This presentation was done a few years ago while I was with CMMI (Now ISACA) as a result it is tied to their Data Management Maturity Model. I talked about analytics, and my colleague on the presentation addressed data maturity.
Also, while I am posting useful things that people keep asking for, here are a set of links that Jeff Gentry did on management frameworks for a Dataversity Webinar. Of particular interest to me was the mapping of the Hoshin Strategic Planning Framework to the CMMI Data Management Maturity Framework. The last link is the actual excel spreadsheet template.
Someone asked the other day if I was still blogging – the answer is yes, but… During the summer I joined the teaching team at University of Maryland to teach a course in data governance and data quality in the Graduate Information Management Program. Between creating the course content and teaching the course, it has consumed all of the creative energy that I normally put into the blog articles.
“Data Prep” has become a popular phrase over the last year or so – why? At a practical level, data preparation tools are providing the same functionality that traditional ETL (extract, transform, load) tools provide. Are data prep tools just a marketing gimmick to get organizations to buy more ETL software? This blog seeks to address why data prep capabilities have become a topic of conversation within the data and analytics communities.
Traditionally, data prep has been viewed as slow and laborious, often associated with linear, rigid methodologies. Recently, however, data prep has become synonymous with data agility. It is a set of capabilities that pushes the boundaries of who has access to data, and how they can apply it to business challenges. Looked at this way, data prep is a foundational capability for digital transformation, which I define as the ability of companies to evolve in an agile fashion in some key dimension of their business model. The business driver of most transformation programs is to fundamentally change key business performance metrics, such as revenue, margins, or market share. Viewed in this way, data prep tools are a critical addition to the toolbox when it comes to driving key business metrics.
Consider the way that data usage has evolved, and the role that data prep capabilities are playing.
Analytics is maturing. Analytics is not a new idea. However, for years it was a function relegated to Operations Research (OR) folks and statisticians. This is no longer the case. As BI and reporting tools grew more powerful and increasingly enabled self service for end users, users began asking questions that were more analytical in nature.
Data-Driven decisions require data “in context.” Decision-making and the process that supports it require data to be evaluated in the context of the business or operational challenge at hand. How management perceives an issue will drive what data is collected and how it is analyzed. In the 1950’s and 1960’s, operations research drove analytics, and the key performance indicators were well established. These included time in process, mean time to failure, yield and throughput. All of these were well understood and largely prescriptive. Fast forward to now. Analytics is broadly applied and used well beyond the scope of operations research. New types of analysis driven in large part by social media trends are much less prescriptive and value is driven by context. Examples include: key opinion leader, fraud networks, perceptual mapping, and sentiment analysis.
Big data is driving the adoption of machine learning. Machine learning requires the integration of domain expertise with the data in order to expose “features” within the data that enhance the effectiveness of machine learning algorithms. The activity that identifies and organizes these features is called “feature engineering.” Many data scientists would not equate “data preparation” with feature engineering, yet there is a strong correlation to what an analyst does. A business analyst invariably creates features as they prepare their data for analysis: 1) observations are placed on a time line; 2) revenue is totaled by quarters and year; 3) customers are organized by location, by cumulative spend, and so on. Data Prep in this context is the organization of data around domain expertise, and is a critical input to the harnessing of big data through automation.
Data science is evolving and data engineering is now a thing. Data engineering focuses on how to apply and scale the insights from data science into an operational context. It’s one thing for a data scientist to spend time organizing data for modest initiatives or limited analysis, but for scaled up operational activities involving business analysts, marketers and operational staff, data prep must be a capability that is available to staff with a more generalized skill set. Data engineering supports building capabilities that enable users to access, prepare and apply data in their day-to-day lives.
“Data Prep” in the context of the above is enabling a broader community of data citizens to discover, access, organize and integrate data into these diverse scenarios. This broad access to data using tools that organize and visualize is a critical success factor for organizations seeking the business benefits of digitally enabling their organization. Future blogs will drill down on each of the above to explore how practitioners can evolve their data prep capabilities and apply them to business challenges.
For those interested in the protection of personal information, the IAPP has an interesting – albeit rather hefty – IAPP-EY Annual Privacy Governance Report 2018, and the NTIA has released its comments from industry on pending privacy regulation. I noted that the IAPP report indicates most solutions are still almost all or entirely manual. I am not sure how this does not become a management nightmare as organizations evolve their data maturity to align operations and marketing more. Data management as a process discipline and some degree of automation are going to be critical capabilities to ensure personal information is protected. There are simply too many opportunities for error when this is done manually.
I recently published an article in TDAN on automating data management and governance through machine learning. It is not just about ML, other capabilities will be required. However, as long as organizations rely on manual processes only, it opens up risk and places the burden on management to enforce policies that are often resisted as they are perceived as a burden on actually doing business. Data management as a process discipline in conjunction with automated processes will reduce operational overhead and risk.
My presentation was on creating audit defensibility that ensures practices are compliant and performed in a way that is scalable, transparent, and defensible; thus creating “Audit Resilience.” Data practitioners often struggle with viewing the world from the auditor’s perspective. This presentation focused on how to create the foundational governance framework supporting a data control model required to produce clean audit findings. These capabilities are critical in a world where due diligence and compliance with best practices are critical in addressing the impacts of security and privacy breaches.
Here is the deck. This was billed as an intermediate presentation and we had a mixed group of business folks and IT people with good questions and dialogue. I am looking forward to the next event.
I fairly consistently get questions on the value of Machine Learning in data management and governance. Sometimes this question is framed at a high level in a very “buzz wordy” way. The person asking the question may not know what machine learning (ML) is. They have just heard the words so many times that they know it is good and should be part of the discussion. At other times, the person asking the question knows about ML and various other analytical techniques, but has never really thought of ML in the context of a data management tool. The challenge is that the emergence of IoT data, Customer 360 programs, and emerging best practices that focus on sharing semantically tagged data, all contribute to a fundamental need to do things differently. Machine learning is one of the tools in the toolbox to address the challenges related to scale, change velocity, and the consistent evolution of users and their use cases.
This post focuses on how we can automate the process of identifying data, classifying it, and linking it to internal and external references to provide semantic meaning. The goal of this post is simply to describe what machine learning is for the data manager, and what tasks it performs in the context of the standards based operational perspective.
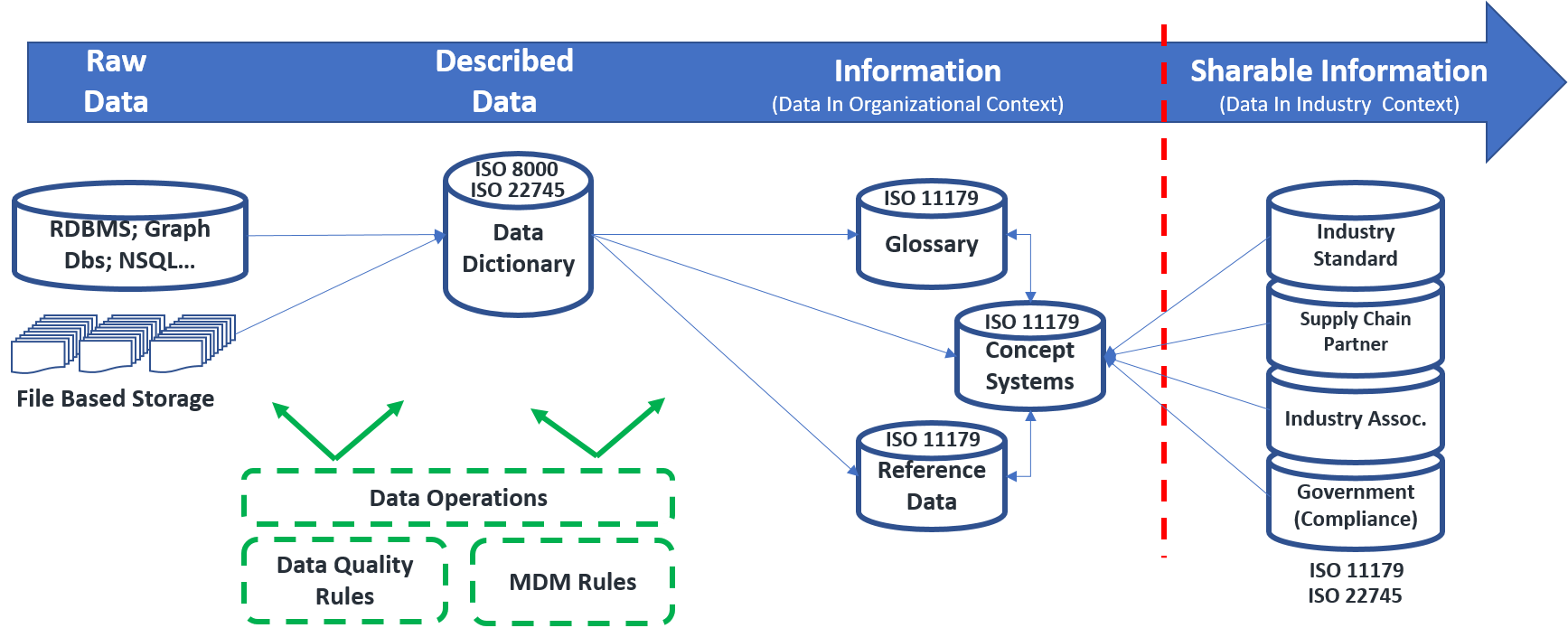
From an operational perspective, the figure below presents the evolution of data from the “raw” transactional state to a highly labelled or curated state that can be shared between purchaser and vendor; or indeed any producer or consumer of data. Machine Learning plays a role in automating how data is curated and enriched across this lifecycle.
Figure 1: The Curation from raw data to sharable Information
If we drill down on the curation lifecycle, we can identify the various repositories that would be required, and a few of the key supporting standards. These standards and their roles are discussed more completely in a follow on post.
Figure 2: The Curation flow across the various repositories required. NOTE that this functional perspective is discussed in the context of a metadata hub in Enterprise Data Management – Where to Start?
The database symbols outlined in blue (solid lines) represent data at rest. The rectangular items outlined in green (dashed lines) represent tasks that automate how data is augmented as it moves along this path. The focus of this discussion is on these green boxes.
Activities within the Data Quality Rules and MDM Rules tasks can be broken down into a number of functional capabilities as detailed below. Some of these capabilities are traditional data operations tasks; namely, persisting metadata in a database, and exposing the data through some sort of cataloging and publishing capability. The other items (outlined in blue) are those where machine learning approaches can be applied.
Figure 3: Functional capabilities supported by Machine Learning
First let’s start with a definition of Machine Learning as Machine Learning has multiple definitions within the popular literature. The website Techemergence provides a comprehensive definition:
“Machine Learning is the science of getting computers to learn and act like humans do, and improve their learning over time in autonomous fashion, by feeding them data and information in the form of observations and real-world interactions.”
Machine learning techniques play a major role in automating the process detailed above especially over unknown or new data sets.
For data management practitioners it is important to understand that no one machine learning technique is going to apply. In all likelihood multiple approaches will be chained together and invariably executed recursively to ensure that the data can be identified, classified and then linked to the appropriate unique identifier. In the ideal world, the algorithms will change or learn to accommodate changes in the data being classified. The figure below lists some of the machine learning techniques that may be applied.
Machine Learning Techniques
Unstructured Data
Structured Data
· Entity Tagging / Extraction
· Categorize
· Cluster
· Summarize
· Tag
· Linking
· Associate
· Characterize
· Classify
· Predict
· Cluster
· Pattern Discovery
· Exception Analysis
Note that these invariably interact with one another. If I tag people entities within unstructured text, I may wish to characterize them using structured technique: count of male names; frequency per document; frequency across documents, etc. This speaks to the layered and recursive nature of machine learning, and the richness of the metadata that the data team will need to manage. For a more technical view of ML techniques see this summary.
These are detailed below with considerations for program managers.
Capability
Considerations
Identify
Machine Learning approaches support the identification of instance data in order to classify the data. Is this personal Information? Does it look like a financial #? Does it reside in a financial statement?
For organizations where there is a significant installed legacy challenge. It will be important to have algorithms that identify data of interest. The identification of personal information is a current area of interest driven by the GDPR regulation.
Classify
Once data is identified, ML approaches support classifying the data within the data dictionary: data is in finance domain; it is in the “Deliver” phase of the Supply Chain Operations Reference (SCOR) lifecycle; etc.
Classification algorithms must exist that tag the data with the appropriate classifier. Capabilities must quantify and resolve those instances where there is uncertainty as to accuracy of the classification algorithm. For example, are we are 100% certain that this is a vendor and not a customer?
Resolve
The completed data dictionary will support entity resolution by providing a richer feature set against which MDM machine learning algorithms can be run.
Resolving the identity of the master data element may require a multi-tiered approach be run iteratively: apply Algorithm #1; for those that do not resolve with Algorithm #1, apply Algorithm #2; etc.
For example, now that I know that have classified the data item as vendor master data (previous step), can I resolve the identity with certainty to identify which vendor it is?
Link
The resolved entity must be linked to internal and external reference sources. Machine Learning techniques may be used to identify and resolve link candidates and specify link type / strength.
The analytical details of this may be addressed in the above “Resolve” capability. However, the focus here should be on identifying the correct link (or links) where there are multiple candidate reference sets where links could be established.
This is a critical step as the linkage to the internal reference “Concept System” is what describes the data element from a semantic perspective. It is also what links the data being described to a publicly available set of definitions that external parties can reference (See “Sharable Information” in figure above). These linkages cross walk an industry accepted definition between supply chain partners.
Example:
If a supply chain manager seeks to communicate the nature of a product requirement to a vendor – a machine screw for example. The ability to specify length of screw versus length of the “shoulder” on the screw; thread size (Metric, standard, imperial?); type of head (hex, square, pan head, etc.) is critical. The internal labels for these are linked to the industry agreed on labels available to the vendor community.
As long as the vendor is using the same reference concept system, both buyer and vendor can be assured that they are talking about the same machine screw.
Once these activities have been completed, the results need to be persisted in a metadata repository and published in a Data Catalog that will allow users to understand what data is available and how it can be accessed.
Some Closing Thoughts :: It’s all about the Ecosystem Maturity!
The above discussion and the content of the two posts in the works on MDM standards and data quality, identifies a set of standards and techniques that seek to streamline and automate the process of Master Data Management. However, these exist within the context of the organization’s data ecosystem. Data practitioners seeking to evolve master data management must ask some core questions regarding information architecture and data management maturity within their ecosystem:
How do these standards support my data strategy?
Do I have a business case?
Executive sponsorship?
Funding?
Does my information architecture support the capabilities that I need to manage Master Data as envisioned by the standards?
Will legacy systems impact how this gets executed?
Does the architecture support a “Service Oriented” metadata registry or catalog concept?
Do I have a metadata catalog?
What are the architectural boundaries and how do I share data across those boundaries?
Do I have the data management maturity to execute?
Identified and scalable processes?
Processes applied consistently across business units?
A governance operating model that can accommodate new functions and the change management overhead?
What controls and metrics exist? Need to be created?
Understanding how standards and machine learning fit within the information architecture and the organization’s capability maturity will enable the data team to define the right strategy and build out a realistic roadmap. For organizations with an established and mature governance function, many of the above questions will be resolved – or the mechanism to resolve them exists. However, for organizations that have less capability maturity, the strategy and roadmap will need to be explicit in identifying the business units where foundational capabilities can be created that can later be adopted across the organizations as the need and maturity evolve.
I was interested to see that Martin Fowler released an article on yet another approach to fixing what is wrong with agile; the Agile Fluency Model. The article provides a good comprehensive write up on this approach. However, go back to look at the links in the above blogs. There are a number of amusing ones. This one from Martin Fowler titled Flaccid Scrum, and these two very amusing ones here and here. They all refer to the same set of challenges facing how agile is implemented.
I am not sure I have anything to add to the debate. however, I do note that successful teams invariably: 1) involve a white board; 2) engage in lively and dynamic dialogue around the challenge; and 3) have team members with an intuitive user centric understanding of the problems the team seeks to solve.
I guess I am also surprised that we are still talking about how to “do” agile!