This presentation is from December 2019 – pre pandemic, and is the last live show I have presented in – I do look forward to getting back into that groove. The following is a write up done by Amber Dennis at DataVersity. Also posted on LLRX.com – here.

Managing Metadata: An Examination of Successful Approaches – DATAVERSITY
Managing Metadata: An Examination of Successful Approaches
By Amber Lee Dennis, 30 Nov 2020
“If Google can deliver results across the entire internet in seconds, why do I have so much trouble finding things in my organization?” asked Jonathan Adams, Research Director at Infogix, at the DATAVERSITY® DGVision Conference, December 2019. In a presentation titled, “I Never Metadata I did Not Like” Adams outlined successful approaches to understanding and managing metadata.
What is Metadata?
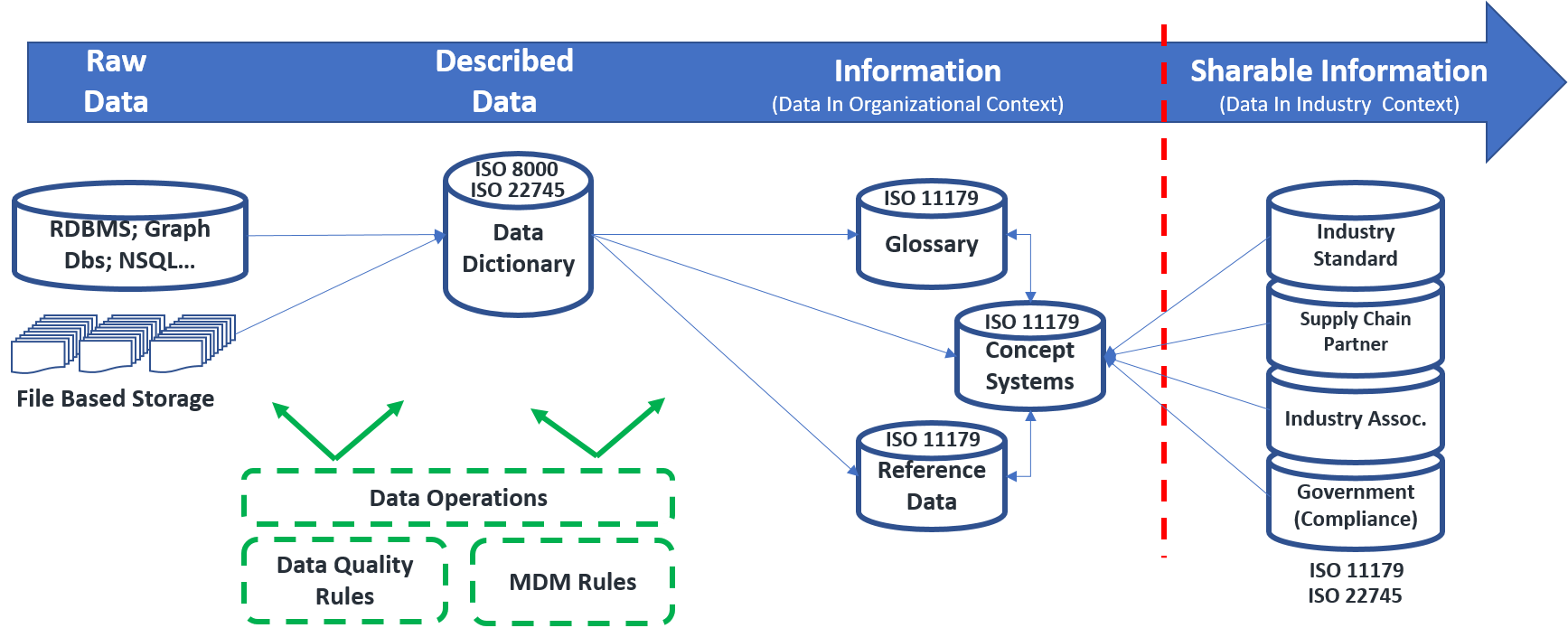
According to the DAMA International Data Management Body of Knowledge (DAMA-DMBoK2), the common definition for metadata, ‘data about data,’ is too simple. Similar to the concept of the card catalog in a library, metadata includes information about technical and business processes, data rules and constraints, and logical and physical data structures. It describes the data itself, the concepts the data represents, and the relationships between the data and concepts. To understand metadata’s purpose, imagine a large library, with hundreds of thousands of books and magazines, but no card catalog. Without the card catalog, finding a specific book in the library would be difficult, if not impossible. An organization without metadata is like a library without a card catalog.
“Obviously it’s data about data, in that sense. We all know that, but also, one person’s data is another person’s metadata. So it gets kind of confusing,” Adams said. Metadata has traditionally focused on technical metadata, which details the structure of data and where it resides, supports IT in managing data, and assists user communities in accessing and integrating data. Reference data, which provides known vocabulary and creates business and operational context along with semantic meaning, is also metadata. Adams said:
“Metadata is kind of everything. It’s how you visualize it, and it’s how you find it. It totally enables data, and in many respects, it’s going to be the bulk of the data you have.”
Types of Metadata
- Descriptive metadata is metadata about the asset, including its title, creator, subject, source, keywords, etc.
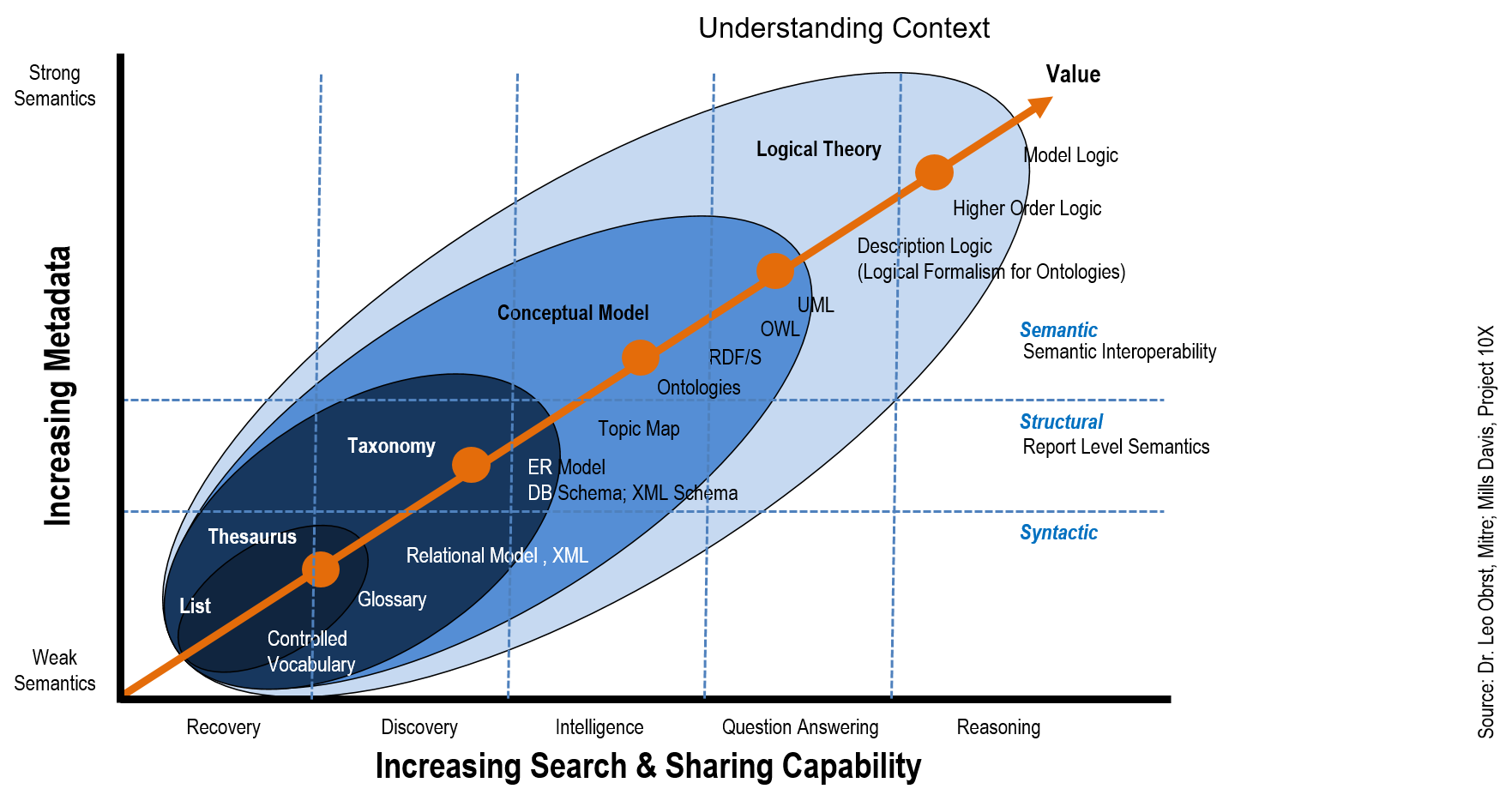
- Content classification metadata details the content and meaning of the data asset. This includes relationships, data models, entities, the business glossary, controlled vocabularies, taxonomies and ontologies.
- Administrative metadata details how to access and use data assets and includes lineage, structure, audit and control, and preservation information.
- Usage metadata indicates how data may be used and how it must be controlled, which includes users, rights, confidentiality and sensitivity.
“And if that isn’t complicated enough,” he said, “those four types of metadata get applied slightly differently depending on where you are.”
Metadata for Operational Systems
Adams provided an illustration of an operational system using a pyramid, with reports on the top level, transactional data on the second level, then functional data on level three, master data on level four, and structural and reference data as the base of the pyramid. Types of data not included in this structure might be a data lake used by marketing, external data, financial information, or CRM data:
“This gets complicated, so we’re going to talk about simplifying it. My point here is that you should drive it from the user perspective, with that use case, view it within this context, and scope it appropriately.”
How Is Metadata Important?
Metadata answers critical questions about data:
- Is the data discoverable?
- Is it understandable?
- Can it be accessed?
- Is it usable?
Success in Metadata Management is shown by how well a team engages and aligns information to the business and operational context of the organization, Adams said. The DMBoK2 says that like other data, metadata requires management. As the capacity of organizations to collect and store increases, the role of metadata management grows in importance. To be data-drive, and organization must be metadata-driven.
Success with Metadata Management
To manage metadata, start with a framework that aligns data to business and operational contexts so that metadata can support Data Governance in the following areas:
- Organizational Impact
- Capabilities and Interfaces
- Programs and Platforms
- Repositories
Adams then further broke down how to address the governance of each of these four areas.
Organizational Impact
Metadata turns critical ‘data’ into critical ‘information.’ Critical information is data + metadata that feeds Key Performance Indicators (KPIs). He recommends asking: “What will change with a better understanding of
your data?” Getting people on board involves understanding how metadata can solve problems for end users while meeting company objectives. “We want to be in a position to say, ‘I do this and your life gets better.’” To have a greater impact, he said, avoid ‘data speak’ and engage with language that the business understands. For example, the business won’t ask for a ‘glossary.’ Instead they will ask for ‘a single view of the customer, integrated and aligned across business units.’ An added benefit of using accessible language is being perceived as helpful, rather than being seen as adding to the workload.
Capabilities and Interfaces
All users must be given the capability to discover information and apply it to challenges, to share critical information, and have access to automated process when available.
- Discover and Understand: A catalog search portal allows users to discover what data is available, place that data in context, and understand who can access it, and how to do so.
- Communicate and Share: Users need the ability to communicate what they’ve produced and make it available for broader consumption. Complete descriptions of data are necessary for compliance and consistency, but must be available in language geared toward the user. The term ‘ETL processing’ may be adequate for an IT user, but terminology such as ‘GDPR compliance’ should also be available so business users have access to the same information.
- Acquire and Integrate: Acquisition and integration varies depending on the perspective of the user and the use case. Administrative metadata enables data consumers to access and integrate data into their environment by clarifying data type, format and access rights. Configuration metadata is important for IT to perform data prep or ETL. Application Programming Interface (API) metadata shows a programmer how to integrate data into a website.
- Integrate and Automate: Interactive metadata supports automated processes for communication and coordination among systems.
Programs and Platforms
Metadata supports reporting and visualization, allowing C-suite members to make better decisions. Metadata enables the transformation of operations allowing the business to grow. Labeling is critical so that data can
move around the organization and be used in innovative ways. Once data is understandable, he said, “You’re going to have people using that data to derive insights that they didn’t even know they didn’t know.”
Data Repositories
Existing information architecture enables – or disables – the depth, scope and quality of available metadata. Adams said that the discussion about repositories is more enterprise architecture-driven, rather than about user needs and business priorities. “It defines what you can do going forward, and it also defines what you cannot do today.”
Reference Architecture
When documenting the Information Architecture, Adams suggests focusing on how the information flows around the architecture of the organization, rather than focusing on specific systems. Start with the type of information and where it resides and denote broad applications and system boundaries. Include data shared with people outside the organization. Although it’s critical to understand what’s happening inside the organization, from a risk perspective, when it comes to risk, it’s more important to understand what’s happening outside the organization. “The interesting thing about this is that you want to use it as a communication tool,” he said. If initially it’s too complex for business users to understand, simplify it a bit. The important thing is to bring people on board.
Data Governance
Often overlooked, governance metadata is Business Intelligence (BI) for your data: metadata about metadata. Metadata ties together Business Strategy, Data Strategy, Data Management and operations with Data Governance. “‘What is the state of my metadata across my ecosystem?’ That’s a bit of a wacky concept for people to grasp.” Enterprise architectures and data reference models are an attempt to align and understand governance policies down to the lower level, Adams said.
Metadata can provide answers to governance questions, such as:
- How do I know I’m doing this correctly?
- What constitutes ‘good’?
- Are we deploying best practices? Are they
defined? - Is this data sufficiently labeled to be
considered ‘governed data?’
Building Capability
As competitive factors in the marketplace continue to evolve and change, the ability to quickly rise to meet those challenges can mean the difference between success and failure. Developing new capabilities, scaling to
meet demand, and controlling risk requires the ability to pull reports using data in ways that are impossible to anticipate in advance, Adams said. “If that’s the environment you want, then you want well-labeled data that allows you to pivot, schema-on-demand kind of activity, and a very flexible perspective.”