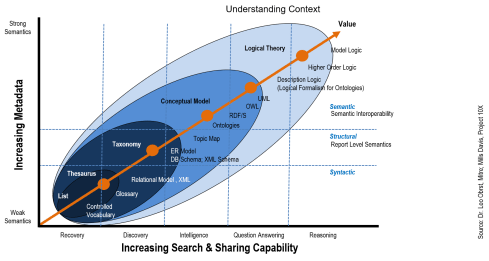
Someone asked me the other day what the business case was for classifying data. For anyone that has engaged with data to perform analytics or produce business intelligence reports, this may seem like a silly question. However, in many minds, the data does not need to be labelled or classified in any way. The data is used by an application and if that application is performing correctly, the data must be good. And, at some level they are right – as long as the data involved never has to be used outside its application, it may never need to be classified or labelled in any way. The data receives all of it semantic context from the application where it is used.
So when does classification become important? It becomes important when data leaves the application that gave it context. For many of our customers this occurs when data leaves the transactional ERP type system, and is moved into a data warehouse or a data lake whose purpose is to provide access to data from multiple sources. Traditionally, this movement from transactional to a more generally accessible repository came with a level of curation. Prior to the concept of the “Data Lake,” data was moved into the data warehouse with the goal of making it the “single source” of truth. This often involved significant levels of data stewardship and curation to reconcile conflicting versions of “truth.” With the growing awareness and adoption of analytics, the idea of a stable concept of “truth” is elusive. The right data for an analyst is context driven and at times highly variable. The Data Lake construct addresses this issue by allowing all data to be loaded so that the user can determine what data to use based on the decision context at the time. This is what data classification enables. Well classified data can be discovered, analyzed, accessed and integrated into a user’s context based on the classification labels that have been exposed to the user in the Data Asset catalog. Based on this perspective, classification is foundational for driving value out of data in the areas of analytics, business intelligence, operational efficiencies, and compliance.
Indeed in the big data space, classification is foundational for analytics, machine learning, the application of higher level logic, and (way up the maturity curve) for building artificial intelligence capabilities. As a foundational building block for Ai, classification is an interesting topic; although for many too abstracted from today’s problems. However, as the foundation for making data discoverable, understandable, accessible and able to be integrated into downstream applications, it is highly relevant to today’s challenges – almost regardless of where your current capabilities stand. For this reason any data management shop should include in its planning a workstream that seeks to evolve classification capabilities
Consider the following uses cases:
Business Intelligence: marketers seeking to report on price sensitivity and are comparing the difference between prices quoted, prices invoiced, and prices paid net of discount. Data across all of the ERP or transactional systems in use must be classified such that the BI Team is assured that all fields marked as “Price” are the correct type of price.
Marketing Analytics: Your customer 360ᵒ program seeks to understand external factors that may have influenced pricing and discounts provided. What customers are related to the prices referenced above? What kind of customers are they (industry, buying frequency, average purchase, …)? How can I correlate those with external events (elections, new regulation, natural disasters, …)? All of this analysis is supported by data that is classified to reflect the types of queries that may occur and analytical operations to be performed.
Operational Efficiency: Your COO wants to ensure that the acquisition process is fully optimized, and seeks to benchmark operations using the SCOR (Supply Chain Operations Reference) Model. The Operations Team downloads the 250 SCOR performance metrics and seeks to map those to the relevant data. Classification supports the ability to find the right data and map it to the data specified in the SCOR Model.
Compliance & Risk Management. Risk teams will rely on well classified data to enable risk models that are robust and flexible in their ability to address evolving risk. This is especially the case for risk associated with adaptive threats; for example fraud and cyber-crime.
Bottom line, if classification is not something that you have thought about, consider putting a plan together. It is the key to releasing the value of your data, and fully leveraging data as an asset.