I fairly consistently get questions on the value of Machine Learning in data management and governance. Sometimes this question is framed at a high level in a very “buzz wordy” way. The person asking the question may not know what machine learning (ML) is. They have just heard the words so many times that they know it is good and should be part of the discussion. At other times, the person asking the question knows about ML and various other analytical techniques, but has never really thought of ML in the context of a data management tool. The challenge is that the emergence of IoT data, Customer 360 programs, and emerging best practices that focus on sharing semantically tagged data, all contribute to a fundamental need to do things differently. Machine learning is one of the tools in the toolbox to address the challenges related to scale, change velocity, and the consistent evolution of users and their use cases.
This post focuses on how we can automate the process of identifying data, classifying it, and linking it to internal and external references to provide semantic meaning. The goal of this post is simply to describe what machine learning is for the data manager, and what tasks it performs in the context of the standards based operational perspective.
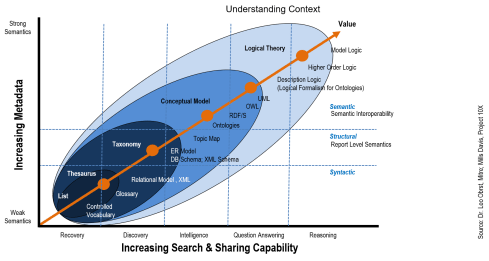
From an operational perspective, the figure below presents the evolution of data from the “raw” transactional state to a highly labelled or curated state that can be shared between purchaser and vendor; or indeed any producer or consumer of data. Machine Learning plays a role in automating how data is curated and enriched across this lifecycle.

Figure 1: The Curation from raw data to sharable Information
If we drill down on the curation lifecycle, we can identify the various repositories that would be required, and a few of the key supporting standards. These standards and their roles are discussed more completely in a follow on post.

Figure 2: The Curation flow across the various repositories required. NOTE that this functional perspective is discussed in the context of a metadata hub in Enterprise Data Management – Where to Start?
The database symbols outlined in blue (solid lines) represent data at rest. The rectangular items outlined in green (dashed lines) represent tasks that automate how data is augmented as it moves along this path. The focus of this discussion is on these green boxes.
Activities within the Data Quality Rules and MDM Rules tasks can be broken down into a number of functional capabilities as detailed below. Some of these capabilities are traditional data operations tasks; namely, persisting metadata in a database, and exposing the data through some sort of cataloging and publishing capability. The other items (outlined in blue) are those where machine learning approaches can be applied.

Figure 3: Functional capabilities supported by Machine Learning
First let’s start with a definition of Machine Learning as Machine Learning has multiple definitions within the popular literature. The website Techemergence provides a comprehensive definition:
“Machine Learning is the science of getting computers to learn and act like humans do, and improve their learning over time in autonomous fashion, by feeding them data and information in the form of observations and real-world interactions.”
Machine learning techniques play a major role in automating the process detailed above especially over unknown or new data sets.
For data management practitioners it is important to understand that no one machine learning technique is going to apply. In all likelihood multiple approaches will be chained together and invariably executed recursively to ensure that the data can be identified, classified and then linked to the appropriate unique identifier. In the ideal world, the algorithms will change or learn to accommodate changes in the data being classified. The figure below lists some of the machine learning techniques that may be applied.
| Machine Learning Techniques | |
| Unstructured Data | Structured Data |
| · Entity Tagging / Extraction
· Categorize · Cluster · Summarize · Tag · Linking |
· Associate
· Characterize · Classify · Predict · Cluster · Pattern Discovery · Exception Analysis |
Note that these invariably interact with one another. If I tag people entities within unstructured text, I may wish to characterize them using structured technique: count of male names; frequency per document; frequency across documents, etc. This speaks to the layered and recursive nature of machine learning, and the richness of the metadata that the data team will need to manage. For a more technical view of ML techniques see this summary.
These are detailed below with considerations for program managers.
| Capability | Considerations |
| Identify | Machine Learning approaches support the identification of instance data in order to classify the data. Is this personal Information? Does it look like a financial #? Does it reside in a financial statement?
For organizations where there is a significant installed legacy challenge. It will be important to have algorithms that identify data of interest. The identification of personal information is a current area of interest driven by the GDPR regulation. |
| Classify | Once data is identified, ML approaches support classifying the data within the data dictionary: data is in finance domain; it is in the “Deliver” phase of the Supply Chain Operations Reference (SCOR) lifecycle; etc.
Classification algorithms must exist that tag the data with the appropriate classifier. Capabilities must quantify and resolve those instances where there is uncertainty as to accuracy of the classification algorithm. For example, are we are 100% certain that this is a vendor and not a customer? |
| Resolve | The completed data dictionary will support entity resolution by providing a richer feature set against which MDM machine learning algorithms can be run.
Resolving the identity of the master data element may require a multi-tiered approach be run iteratively: apply Algorithm #1; for those that do not resolve with Algorithm #1, apply Algorithm #2; etc. For example, now that I know that have classified the data item as vendor master data (previous step), can I resolve the identity with certainty to identify which vendor it is? |
| Link | The resolved entity must be linked to internal and external reference sources. Machine Learning techniques may be used to identify and resolve link candidates and specify link type / strength.
The analytical details of this may be addressed in the above “Resolve” capability. However, the focus here should be on identifying the correct link (or links) where there are multiple candidate reference sets where links could be established. This is a critical step as the linkage to the internal reference “Concept System” is what describes the data element from a semantic perspective. It is also what links the data being described to a publicly available set of definitions that external parties can reference (See “Sharable Information” in figure above). These linkages cross walk an industry accepted definition between supply chain partners. Example: If a supply chain manager seeks to communicate the nature of a product requirement to a vendor – a machine screw for example. The ability to specify length of screw versus length of the “shoulder” on the screw; thread size (Metric, standard, imperial?); type of head (hex, square, pan head, etc.) is critical. The internal labels for these are linked to the industry agreed on labels available to the vendor community. As long as the vendor is using the same reference concept system, both buyer and vendor can be assured that they are talking about the same machine screw. |
Once these activities have been completed, the results need to be persisted in a metadata repository and published in a Data Catalog that will allow users to understand what data is available and how it can be accessed.
Some Closing Thoughts :: It’s all about the Ecosystem Maturity!
The above discussion and the content of the two posts in the works on MDM standards and data quality, identifies a set of standards and techniques that seek to streamline and automate the process of Master Data Management. However, these exist within the context of the organization’s data ecosystem. Data practitioners seeking to evolve master data management must ask some core questions regarding information architecture and data management maturity within their ecosystem:
- How do these standards support my data strategy?
- Do I have a business case?
- Executive sponsorship?
- Funding?
- Does my information architecture support the capabilities that I need to manage Master Data as envisioned by the standards?
- Will legacy systems impact how this gets executed?
- Does the architecture support a “Service Oriented” metadata registry or catalog concept?
- Do I have a metadata catalog?
- What are the architectural boundaries and how do I share data across those boundaries?
- Do I have the data management maturity to execute?
- Identified and scalable processes?
- Processes applied consistently across business units?
- A governance operating model that can accommodate new functions and the change management overhead?
- What controls and metrics exist? Need to be created?
Understanding how standards and machine learning fit within the information architecture and the organization’s capability maturity will enable the data team to define the right strategy and build out a realistic roadmap. For organizations with an established and mature governance function, many of the above questions will be resolved – or the mechanism to resolve them exists. However, for organizations that have less capability maturity, the strategy and roadmap will need to be explicit in identifying the business units where foundational capabilities can be created that can later be adopted across the organizations as the need and maturity evolve.
For an additional perspective on the business cases that might drive ML, see Classification – the key to releasing data’s value !