Happy New Year!
This entry has been sitting in my “to publish” file for some time. There is much more to be said on the topic. however, in the interest of getting it out … enjoy!
=======================================================
This entry was prompted by the article in the INFORMS ANALYTICS Magazine article titled Forensic Analytics: Adapting to a Growing Pandemic by Priti Ravi who is a senior manager with Mu Sigma and specializes “in providing analytics-driven advisory services to some of the largest retail, pharmaceutical and technology clients spread across the United States.”
Ms. Ravi writes a good article that left me hanging. Her conclusion was that the industry lacks access to sophisticated and intelligent monitoring equipment, and there exists a need for a “robust fraud management systems” that “offer a collective set of techniques” to implement a “complex adaptive approach.” I could not agree more. However, where are these systems? Perhaps even what are these systems?
Adaptive Approaches
To the last question first. What is a Complex Adaptive Approach? If you Google the phrase, the initial entries involve biology and ecosystems. However, wikipedia’s definition encompasses medicine, business and economics (amongst others) as areas of applicability. From an analytics perspective, I define complex adaptive challenges as those that are impacted by the execution of the analytics – by doing the analysis, the observed behaviors change. This is inherently true of fraud as the moment perpetrators understand (or believe) they can be detected, behavior will change. However, it also applies to a host of other type of challenges: criminal activity, regulatory compliance enforcement, national security; as well as things like consumer marketing and financial investment.
In an article titled Images & Video: Really Big Data the authors (Fritz Venter the director of technology at AYATA; and Andrew Stein the chief adviser at the Pervasive Strategy Group. define an approach they call “prescriptive analytics” that is ideally suited to adaptive challenges. They define prescriptive analytics as follows:
“Prescriptive analytics leverages the emergence of big data and computational and scientific advances in the fields of statistics, mathematics, operations research, business rules and machine learning. Prescriptive analytics is essentially this chain of transformations whereby structured and unstructured big data is processed through intermediate representations to create a set of prescriptions (suggested future actions). These actions are essentially changes (over a future time frame) to variables that influence metrics of interest to an enterprise, government or another institution.”
My less wordy definition: adaptive approaches deliver a broad set of analytical capabilities that enables a diverse set of integrated techniques to be applied recursively.
What Does the Robust Solution Look Like?
Defining adaptive analytics this way, one can identify characteristics of the ideal “robust” solution as follows:
- A solution that builds out a framework that supports the broad array of techniques required.
- A solution that is able to deal with the the challenges of recursive processing. This is very data and systems intensive. Essentially for every observation evaluated, the system must determine whether or not the observation changes any PRIOR observation or assertion.
- A solution that engages users and subject matter experts to effectively integrate business rules. In an environment where traditional predictive analytic models have a short shelf life (See Note 1), engaging with the user community is often the mechanism to quickly capture environmental changes. For example, in the banking world, tracking call center activity will often identify changes in fraud behavior faster than a neural network set of models. Engaging the User in the analytical process will require user interfaces, and data visualization approaches that are targeted at the user population, and integrate with the organization’s work processes. Visualization will engage non technical users to help them apply their experience and intuition to the data to expose insights. The census bureau has an interesting page, and if you look at Google Images, you can get an idea of visualization approaches.
- A solution that provides native support for statistical and mathematical functions supporting activities associated with data mining : clustering, correlation, pattern discovery, outlier detection, etc.
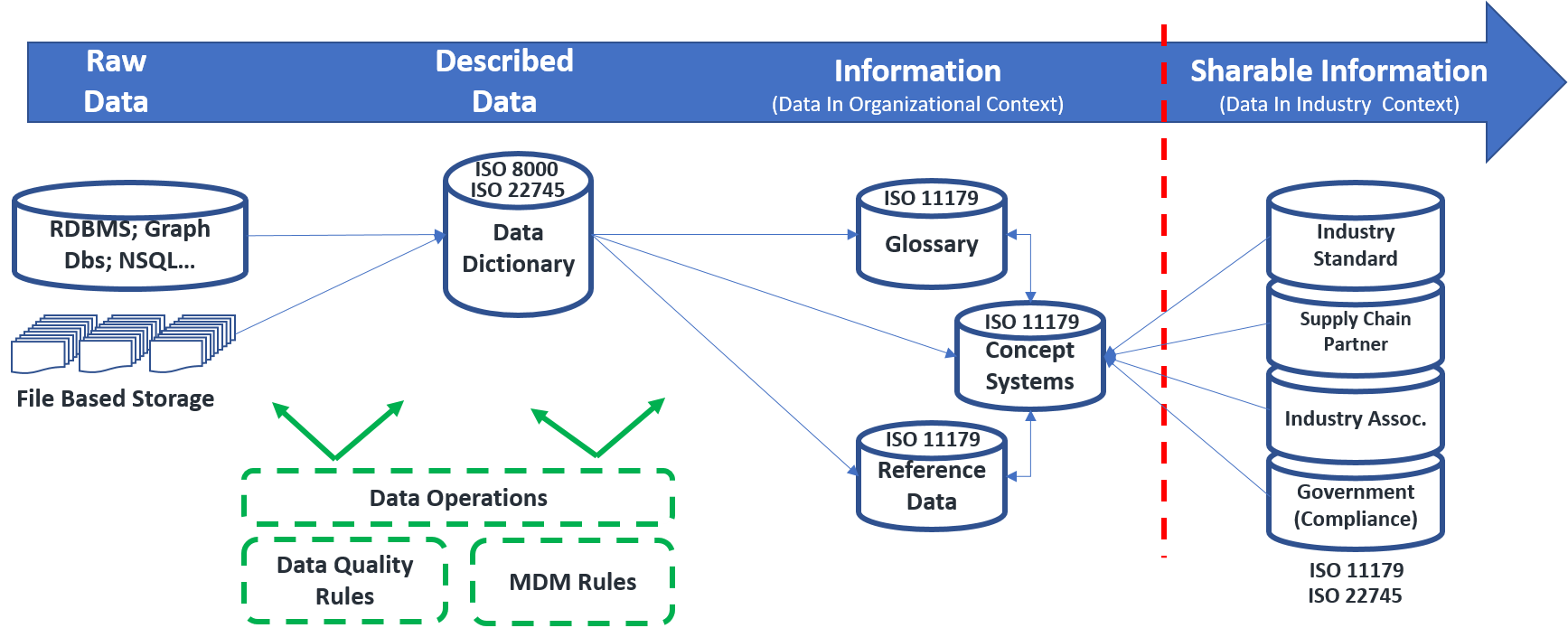
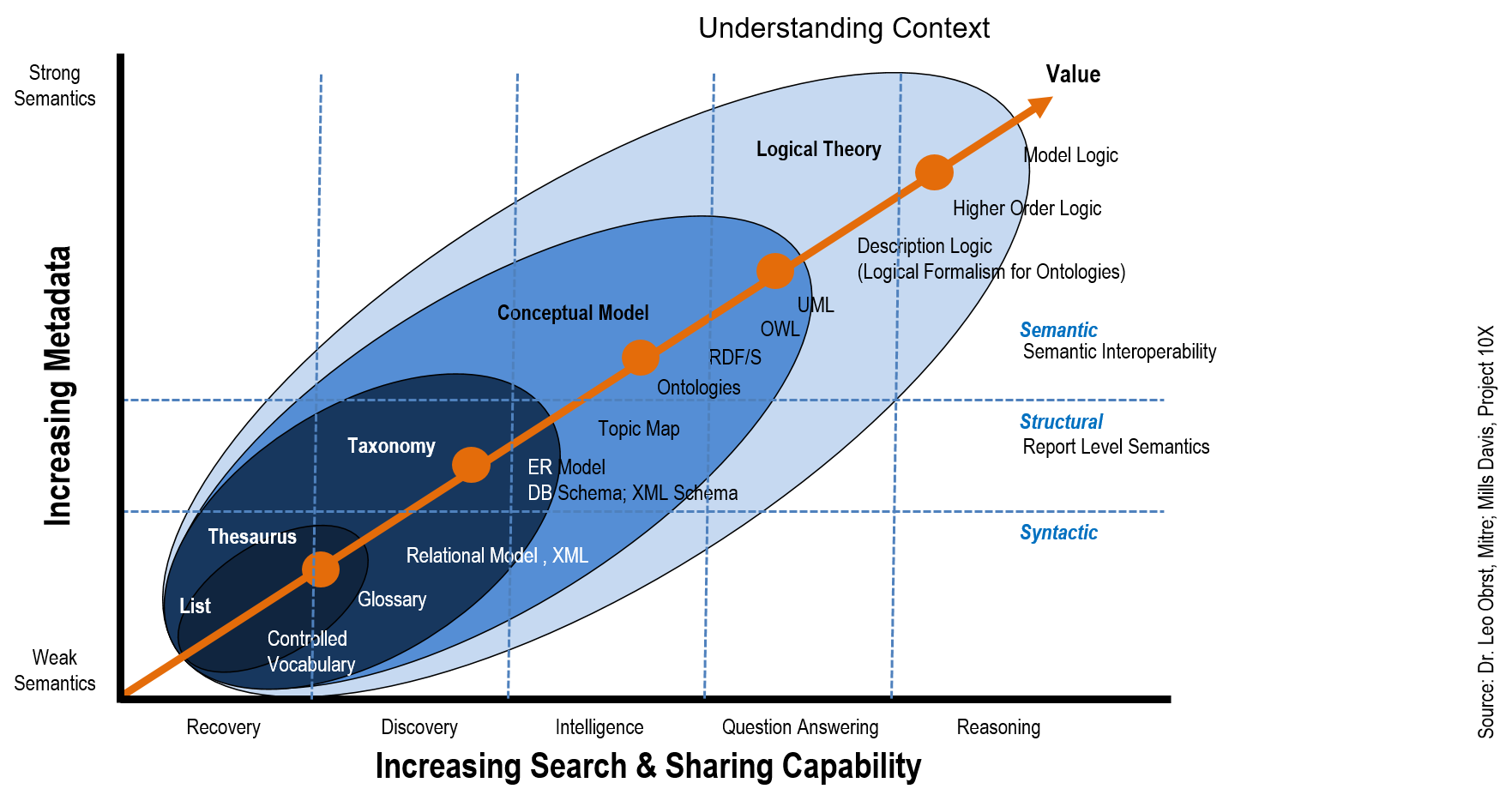
- A solution that structures unstructured data: categorize, cluster, summarize, tag/extract. Of particular importance here is the ability to structure text or other unstructured data into taxonomies or ontologies related to the domain in question.
- A solution that persists data with the rich set of metadata required to support complex analytics. While it is clearer why unstructured data must be organized into a taxonomy / ontology, this also applies to structured data. Organizing data consistently across the variety of sources allows non obvious relationships to be exposed, and application of more complex analytical approaches.
- A solution that is relatively data agnostic – data will come from many places and exist in many forms. The solution must manage the diversity and provide a flexible way to integrate new data into the analytical framework.
What are Candidate Tools ?
And now to the second question: where are these tools? It is hard to find tools that claim to be “adaptive analytic” tools; or “prescriptive analytics” tools or systems in the sense that I have described them above. I find it interesting that over the last five years, major vendors have subsumed complex analytical capabilities into a more easily understandable components. Specifically, you used to be able to find Microsoft Analytical Services easily on their site. Now it is part of MS SQL Server as SSAS; much the same way that the reporting service is now part of the database offer as SSRS (reporting services). There was a time a few years ago when you had to look really hard on the MS site to find Analytical Services. Of course since then Microsoft has integrated various BI acquisitions into the offer and squared away their marketing communication. Now their positioning is squarely around BI and the database. Both of these concepts are easier to sell at the executive level, than the notion of prescriptive or adaptive analytics.
The emergence of databases and appliances optimized around analytics has simplified the message on the data side. everyone knows they need a database, and now they have one for analytics. At the decision maker level, that is a much easier decision than trying to figure out what kind of analytical approach the organization is going to adopt. People like Teradata have always supported analytics through the integration of SAS and now R as in-database functionality. However, Greenplum, Neteeza and others have incorporated SAS and the open source analytical “R” . In addition, we have seen the emergence (not new but much more talked about it seems) of the columnar database. The one I hear about most is the Sybase IQ product; although there have been a number of posts on the topic on here, here, and here.
My point here is that vendors have too hard a time selling complex analytical solutions, and have subsumed the complex capabilities into the concepts that are easier to package, position and communicate around; namely; database products and Business Intelligence products. The following are product sets that are candidates for the integrated approach. We start with the big players first and work towards that are less obviously candidates.
SAS
The SAS Fraud Framework provides an integration of all the SAS components that required to implement a comprehensive analytics solution around adaptive challenges (all kinds of fraud, compliance, money laundering, etc. as examples). This is a comprehensive suite of capabilities that spans all activities: data capture, ingest, and quality; analytics tools (including algorithm libraries), data visualization and reporting / BI capabilities. Keep in mind that SAS is a company that sells the building blocks, and the Fraud Framework is just that, a framework within which customers can build out capabilities. This is not a simple plug and play implementation process. It takes time and investment and the right team within the organization. The training has improved, and it is now possible to get comprehensive training.
As with any implementation of SAS, this one comes with all the caveats associated with comprehensive enterprise systems that integrate analytics into the fabric of an organization. The Gartner 2013 BI report indicates that SAS “very difficult to implement”. This theme echoes across the product set. Having said that when it comes to integrated analytic of the kind we have been discussing all, of the major vendors suffer from the same implementation challenges – although perhaps for different reasons.
Bottom line however, is that SAS is a company grounded in analytics – the Fraud Framework has everything needed to build out a first class system. However, the corporate culture builds products for hard core quants, and this is reflected in the Gartner comments.
IBM
IBM is another company that has the complete offer. They have invested heavily in the analytics space, and between their ETL tools; the database/ appliance and Big Data capabilities; the statistical product set that builds off SPSS; and, the Cognos BI suite users can build out the capabilities required. Although these products are being integrated into a seamless set of capabilities, they remain somewhat separate and this probably explains some of the implementation challenges reports. Also, the product side of the IBM operation does not necessarily speak with the Global Services side of the house.
I had thought when IBM purchased Systems Research & Development (SRD) in 2005 that they were going to build out capabilities that SRD and Jeff Jonas had developed. Jeff heads up the Entity Analytics group within IBM Research, and his blog is well worth the read. However, the above product set appears to have remained separated from the approaches and intellectual knowledge that came with SRD. This may be on purpose – from a marketing perspective, buy the product set, and then buy IBM services to operationalize the system is not a bad approach.
Regardless, as the saying goes, no one ever got fired for buying IBM” probably still holds true. However, like SAS beware of the implementation! Any one of the above products (SPSS, Cognos, and Infosphere) require attention when implementing. However, when integrating as an operational whole, project leadership needs to ensure that expectations as to the complexity and time frame are communicated.
Other Products
There are many other product sets and I look forward to learning more about them. Once I post this, someone is going to come back and mention “R” and other open source products. There are plenty out there. However, be aware that while the products may be robust, many are not delivered as an integrated package.
With respect to open source tools, it is worth noting that the capabilities inherent in Hadoop – and the related products, lend themselves to adaptive analytics in the sense that operators can consistently re-link and re-index on the fly without having to deal with where and how the data is persisted. This is key in areas like signals intelligence, unstructured data analysis, and even structured data analysis where the notion of semantic equivalence is shifting. This is a juicy topic all by itself and worthy of a whole blog entry.
Notes:
- Predictive analytics relies on past observations to predict future observations. In an adaptive environment, the inputs to those predictive models continually change as a result of the outputs using the past observations.
Tags: Adaptive, analytics, best practices, Big Data, BRE BRMS Adaptive, Prescriptive, products