
Very positive outlook on the BI space – Cloud will bring it to the masses; visualization will make it understandable.
We need to think about ETL differently!
26 JanThis blog was started to write about analytics – so here I go again on ETL! Seems that if you are working on Big Data things, it always starts with the data, and in many respects that is the thing that is most difficult – or perhaps requires the most wrenching changes – See this Creating an Enterprise Data Strategy for some interesting facts on data strategies.
ETL is a chore at the best of times. Analysts are generally in a rush to get data into a format that supports the analytical task of the day. Often this means taking the data from the data source and performing the data integration required to make the data analytically ready. This is often done at the expense of any effort by the data management folks to apply controls oriented at data quality issues.
This has created a tension between the data management side of the house and the analytical group. The data management folks are focused on getting data into an enterprise Warehouse or DataMart in a consistent format with data defined and structured in accordance with definitions and linkages defined through the data governance process. Analysts on the other hand – especially those engaged in adaptive type of analytical challenges – seem always to be looking at data through a different lens. Analysts often want to apply different entity resolution rules; want to understand new linkages (implies new schema); and, generally seek to apply a much looser structure to the data in order to expose insights that are often hidden by the enterprise ETL process.
This mismatch in requirements can be addressed in many ways. However, a key starting step is to redefine the meaning of ETL within an organization. I like the definition attributed to Michael Porter where he defines a “Lifecycle of Transformation” that shows how data is managed from the raw or source state through to application in a business context (Larger Image)

Value Chain of Transformation
I am pretty sure that Michael Porter does not think of himself as an ETL person, and the article (Page 14) I obtained this from indicates that this perspective is not ETL. However, I submit that the perspective that ETL stops once you have data in the Warehouse or the DataMart is just too limiting, and creates a false divide. Data must be both useable and actionable – not just useable. By looking at the ETL challenge across the entire transformation (does that make ETL TL TL TL …?), practitioners are more likely to meet the needs of business users.
Related discussions for future entries:
- Wayne Eckerson has a number of articles on this topic. My favorite: Exploiting Big Data Strategies for Integrating with Hadoop by Wayne Eckerson; Published: June 1, 2012.
- The limitations placed on analytics through the application of a schema independent of the analytical context is one of the drawbacks of “old school” RDBMS. The ability of a file based Hadoop / mapreduce oriented analytical environment to apply the schema later in the process is a key benefit of Hadoop/Mapreduce.
Open Source versus COTS
26 JanPublic Sector Big Data: 5 Ways Big Data Must Evolve in 2013
Much of this article rings true. However, the last section requires some explanation:
“One could argue that as open source goes in 2013, Big Data goes as well. If open source platforms and tools continue to address agency demands for security, scalability, and flexibility, benefits within from Big Data within and across agencies will increase exponentially. There are hundreds of thousands of viable open source technologies on the market today. Not all are suitable for agency requirements, but as agencies update and expand their uses of data, these tools offer limitless opportunities to innovate. Additionally, opting for open source instead of proprietary vendor solutions prevents an agency from being locked into a single vendor’s tool that it may at some point outgrow or find ill-suited for their needs.”
I take exception to this in that the decision to go open source versus COTS is really not that simple. It really depends on a number of things: the nature of your business; the resources you have available to you; and the enterprise platforms and legacy in place to name a few. If you implement a COTS tool improperly you can be locked into using that tool – just the same as if you implement an Open Source tool improperly.
How locked in you are to any tool is largely a question of how the solution is architected! Be smart and take your time ensuring that the logical architecture ensures the right level of abstraction that ensures a level of modularity; and thus flexibility. This article talks about agile BI architectures – we need to be thinking the same way system architectures.
My feeling is that we are headed to a world where COTS products work in conjunction with Open Source – currently there are many examples of COTS products that ship with Open Source components – how many products ship with a Lucene indexer for example?
Dealing with Fragmented Metadata
15 JanThe overall challenge is one of sorting out the metadata management within the organization. Presumably this is creating data quality problems of some sort.
It is somewhat hard to evaluate the metadata question in the absence of a few other data points, as metadata is everywhere, and is influenced by numerous factors: overall data management policies, the information architecture, the system architecture, and the security policies to name a few. Additionally, there is often a mis-alignment between these factors and how the organization’s management structure supports data management best practices.
First step – define the data quality issue. This breaks out along three dimensions: 1. how users find and retrieve data assets; 2. How data is delivered; and, 3. how data is managed.
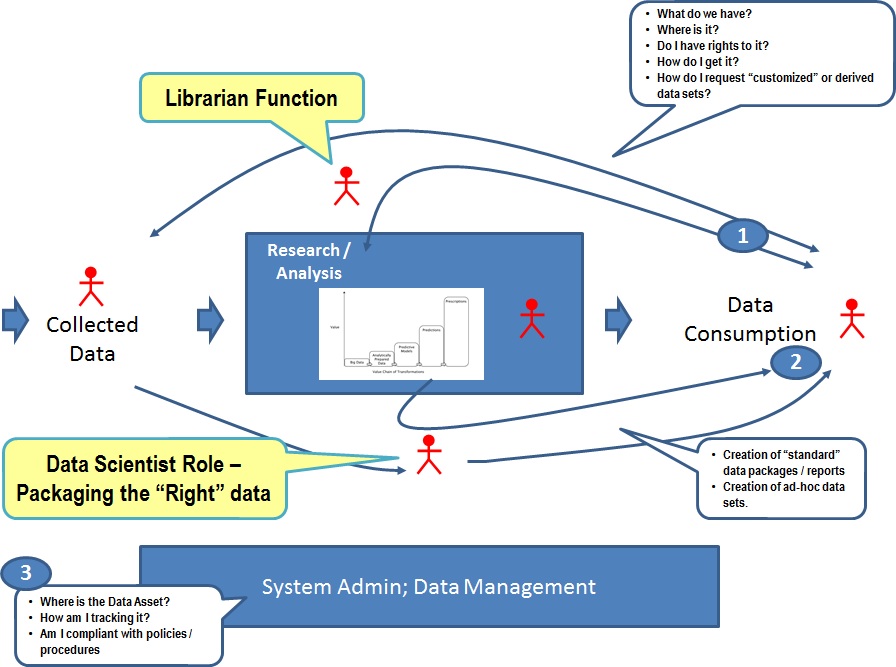
Breaking data down along these dimensions will expose the function that is creating the duplication and the kind of metadata involved.
Additionally viewing the problem this way will address how the organization is thinking about the process. How is the library function addressed? Is there a cataloging function that keeps an inventory of all data assets available to the organization? Is there a role of data scientist – perhaps data “packager” is a better term for most organizations. Is there an organizational element to why metadata is getting fragmented? An example of this would be that the Librarian function is organizationally part of the Research Division. Data collection and packaging is an IT function. The Library software that manages the search and cataloging functions is managed separately from the metadata management system supporting the data warehouse. Anything done by Research creates fragmentation, and possibly duplication of metadata.
Once this perspective is applied, one gets a better idea of the impact related to the data quality problem. Issues of a cumbersome search interface, can be addressed in the short term through better training, or increased resources on the help desk. However, security or audit related shortcomings might result in a security breach which would have much greater impact.
So what to do? Clearly this is not just a metadata problem. In many organizations, the challenge of duplicated metadata is created by legacy environments that have grown fragmented over time. The roadmap that defines the path forward will be unique for each organization. However, a few best practices are called for.
- Creation of an information architecture / framework that all can agree on.
- Creation of an agreed on set of “states” that can be applied to data assets that are flowing though this information architecture.
- Creation of a policy/process/standards matrix that defines how these are applied to data assets based on where they are in the information architecture
- The above implies that there is a data governance component within the organization’s management structure – if this does not exist, it needs to be established.
From a platform perspective there are two best practice considerations: a metadata registry should be evaluated; and metamodels created by which all metadata are viewed. The registry is most important, as it imposes a discipline on the metadata management process.
Think of a metadata registry as the “reference data” or the “controlled vocabulary” for metadata. For any given data asset, it defines what metadata one should expect to see. If it is not in the metadata registry, it should not exist. All of the IT tools that are engaged in moving, enhancing or creating derived works from data assets should use the metadata registry as the reference source for all activity related to metadata. This reduces the likelihood that metadata will need to be duplicated, and if it is duplicated, it reduces the likelihood that it is duplicated incorrectly.
This is managed by the ISO 11179 specification. My sense is that the development of a metadata registry is something that comes with Big Data. Just like reference data, and master data, metadata is a management challenge that is supported by IT capabilities NOT the other way around.
Link
Is this the rebirth of Sybase?
2 JanIs this the rebirth of Sybase?
Sybase + Hana a potentially powerful combo?
Business Rules Engines & “Prescriptive Analytics”
24 DecSomeone asked me the other day about how to best evaluate business rule engines (BRE) or business rules management systems (BRMS). The following were the quick notes. BRE are part of a solution. I like what this month’s INFORM magazine said when talking about “Prescriptive Analytics” (page 14); which I find falls into the same category of “Adaptive Analytics”. They define prescriptive analytics as follows:
“Prescriptive analytics leverages the emergence of big data and computational and scientific advances in the fields of statistics, mathematics, operations research, business rules and machine learning. Prescriptive analytics is essentially this chain of transformations whereby structured and unstructured big data is processed through intermediate representations to create a set of prescriptions (suggested future actions). These actions are essentially changes (over a future time frame) to variables that influence metrics of interest to an enterprise, government or another institution.”
With that in mind to frame a discussion of BRMS…
Why was the BRE created? Different companies have approached things differently, which has resulted in differing feature sets. TIBCO has a rules engine that was built around their Enterprise Service Bus (ESB) business; SAS has a rules engine feature that is organized around processing rules within the construct of the various analytical packages (money laundering; fraud); Streambase has a rules engine optimized around applying “real time” rules in streaming data within the financial trading data.
Many BRE / BRMS started as workflow or content management tools, and conflate the idea of a rules engine with workflow related management. This is important to understand as certain applications of BRE need to be extracted away from the workflow management aspect of things
The above tends to frame why BRE products are built the way they are. However, there are a core set of capabilities that exist within all rules engines:
Rule Management. Does the BRMS provide the rules authoring environment that is appropriate for the particular installation? One is looking for the ability of the rules authoring approach to support a level of abstraction around how business entities are identified and how rules are applied to those entities (Business Entity Model).
How does the BRMS support the ability to evaluate current rules and re-use rules, or portions of rules? This is related to how the BRMS supports the evolution of rules in order to optimize them.
Processing functions: When creating rules, what functions exist within the rules authoring component of the engine that can be called on by the user? This discussion falls into two categories:
- Functions that are universal – think of these as functions that are similar to those available excel: sum; count; average; absolute value, etc.
- Functions that are external to the rules engine but whose invocation is handled by the tool.
The latter is perhaps most important from an analytical perspective in that few rules engines appear to have capabilities to apply a complex rule based on a native set of functions. Additionally, the ability to call external functions, or integrate non-BRE logic, impacts a BRE’s ability to deal with file based data and the associated processing that is part of the Hadoop / MapReduce approach to the Big Data challenge.
How rules are triggered. How does the tool support rule management from a processing perspective? In complex event processing there needs to be a way to manage when rules are executed. This becomes important when a collection of rules must be executed only on receipt of all the data required. This particular perspective is framed by how the solution has been architected. In general, there is a desire to reduce the input / output activity with the data source(s) if that activity does not produce an actionable result.
Sourcing the input. What functions are native to the BRE that provides access to data? Are there connectors to all the major databases; unstructured sources; web sites (open source); file systems? This is perhaps less of an issue than it used to be as the notion of data virtualization has evolved and tools are available to easily format data for delivery to the BRE/
Interfaces. What interface capabilities exist to all of the BRE components? Does the BRE have well published API’s that expose the functions required to effectively integrate the tool into the overall workflow. The ability to reach into the system to expose information of interest is critical. This is most important from an operational perspective. In the management of complex event processing rules, the ability to look into the system and create a simplified view of what can be an overwhelming level of data is critical.
See also:
- December Informs magazine article on analysis of imagery and “Presecriptive Analytics” This frames the discussion on the combination of capabilities that needs to exist in a decision support capability for complex and adaptive problems; a rules based approach is one f the capabilities.
- Semantic Reasoning
- Complex Event Processing
Link
Success of TSA’s Risk-Based Security Focus Hard To Gauge
14 DecSuccess of TSA’s Risk-Based Security Focus Hard To Gauge
I like the idea of randomizing the approach. TSA says it is to keep the staff awake. however, it also serves to look at things from a new angle, and potentially identify new issues.
Link
Palantir’s marketing machine never ceases to amaze me!
11 DecWell Palantir has done it again – check out this article . I like this product, and the folks that built it have done a good job. however, it never ceases to amaze me at how well they market. Have you been to the web site – www.palantir.com/ ? Plenty of videos and glossies, but little technical information – A polar opposite to the SAS web site – www.sas.com/ . I am not sure of the technical or product underpinning of the Distributed Common Ground System (DCGS) that Raytheon put together, but it appears that it may be heading the way of other “Big Bang” approaches http://www.raytheon.com/capabilities/products/dcgs/ . If anyone has any insights into the products underlying the DCGS let me know. But back to my point – Palantir gets a shout out from the Army, and they are the only company mentioned – nice. You cannot pay for that kind of marketing.
